Code
library(tidyverse)
library(scales)
library(class)
library(caret)Predicting categorical class membership is one of two big areas of machine learning (the other being predicting a continuous response – e.g., regression). The idea behind kNN is simple. For an unclassified sample, the algorithm finds some number (\(k\)) of samples that are close by in a parameter space and classifies the unknown sample by the class membership of the nearest neighbors. It’s an appealing and intuitive approach.
library(tidyverse)
library(scales)
library(class)
library(caret)As usual we’ll want tidyverse(Wickham 2023) and caret(Kuhn 2024) for cross validation. We’ll be scalining with scales(Wickham, Pedersen, and Seidel 2025) and running kNN with class(Ripley 2025).
Chapter 3: Lazy Learning – Classification Using Nearest Neighbors in Machine Learning with R: Expert techniques for predictive modeling, 3rd Edition. Link on Canvas.
Most machine learning tasks come down to prediction, right? When the response variable (the left hand side of the equation) is categorical we call this classification. The kNN algorithm is a very simple but effective classifier that goes back to the 1950s and assigns membership to an unknown sample based on its proximity to known samples. It’s used quite a bit because of its simplicity and often seen as a “recommender” algorithm (e.g., Netflix, Spotify, Amazon). We will learn more about other (slicker?) methods like neural nets later on but kNN is still a workhorse in the classification game.
In ML, we spend a lot of time and effort thinking about the relationships between samples as described by many (maybe related, maybe independent) variables. In the classic Palmer Penguin data we’ve used there is categorical data on species, sex, and island for each bird. And we have continuous measurements of bill length, bill depth, flipper length, body mass. That is, for the continuous data, we have a four dimensional space in which we can characterize each bird. In ML applications we will deal with high dimensional space all the time. In fact we often have so many dimensions that we reduce them to more manageable sizes using tools like PCA.
Algorithms like kNN work just fine in high dimensional space. But that doesn’t mean you can just chuck variables in without thinking about what they are because they all get weighted equally. As the number of dimensions increases, distances between points tend to become more similar to one another. This means that the idea of a “nearest” neighbor can start to break down - a common issue referred to as the curse of dimensionality. Adding predictors does not automatically improve kNN performance.
Let’s review Euclidean distance which will help make sense of how you think about variables.
Between your coursework here, in ESCI 503, and in ESCI 505 you’ll have had a bellyful of Euclidean distance (and other distance measures in ESCI 503) by the time June rolls around. But just to cover all the bases, here is a quick example of how we get distances in 1D (one dimension), 2D, 3D, and then \(n\)D. The key point is that distance is computed across all predictors simultaneously, with each contributing equally once variables are on the same scale.
One dimension is easy, right? If we have two points (\(p\) and \(q\)) at \(p=3\) and \(q=10\) we know that the distance between them is \(d(p,q) = \sqrt{(q - p)^2} = 7\), right?
p <- 3
q <- 10
sqrt((q-p)^2)[1] 7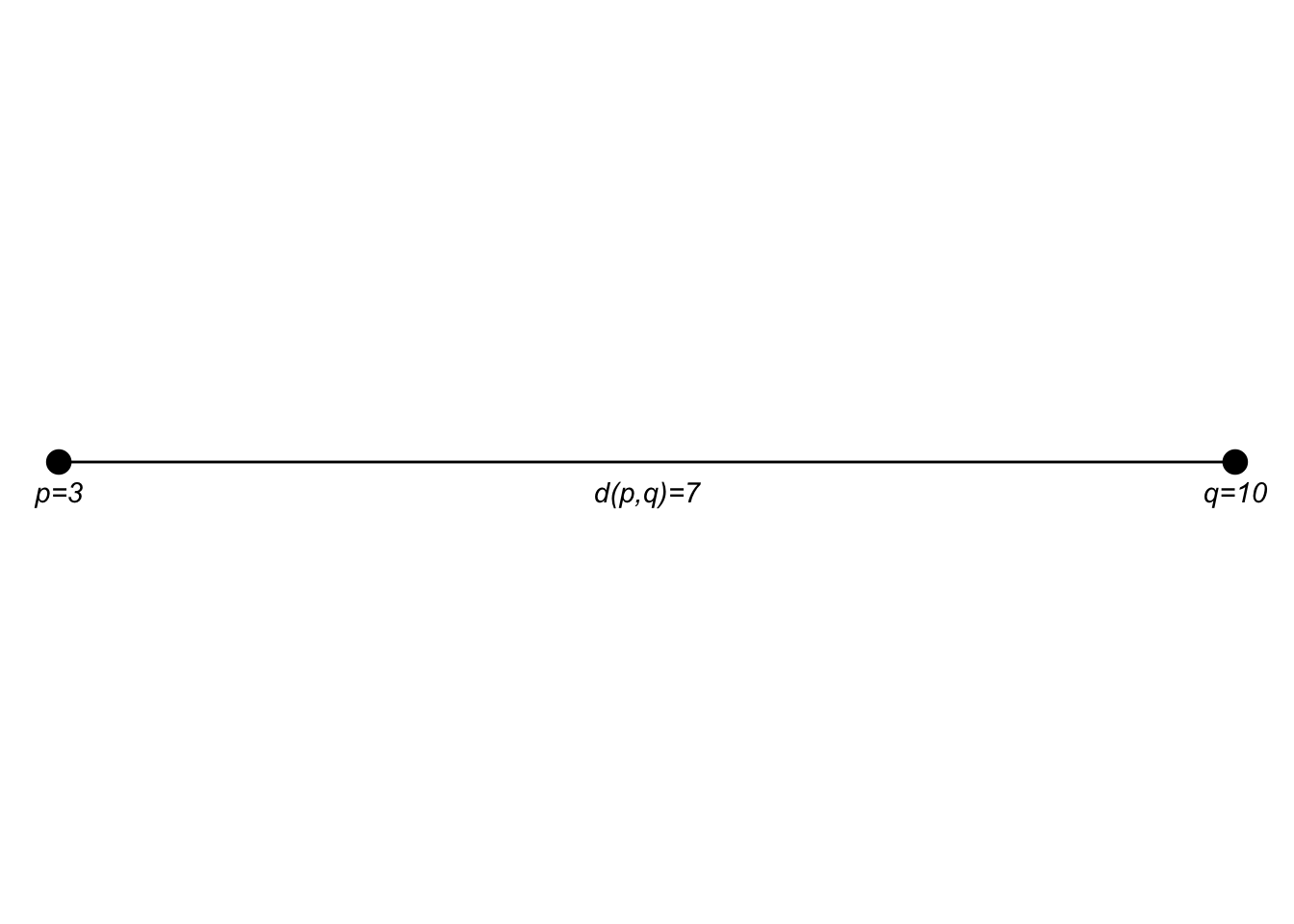
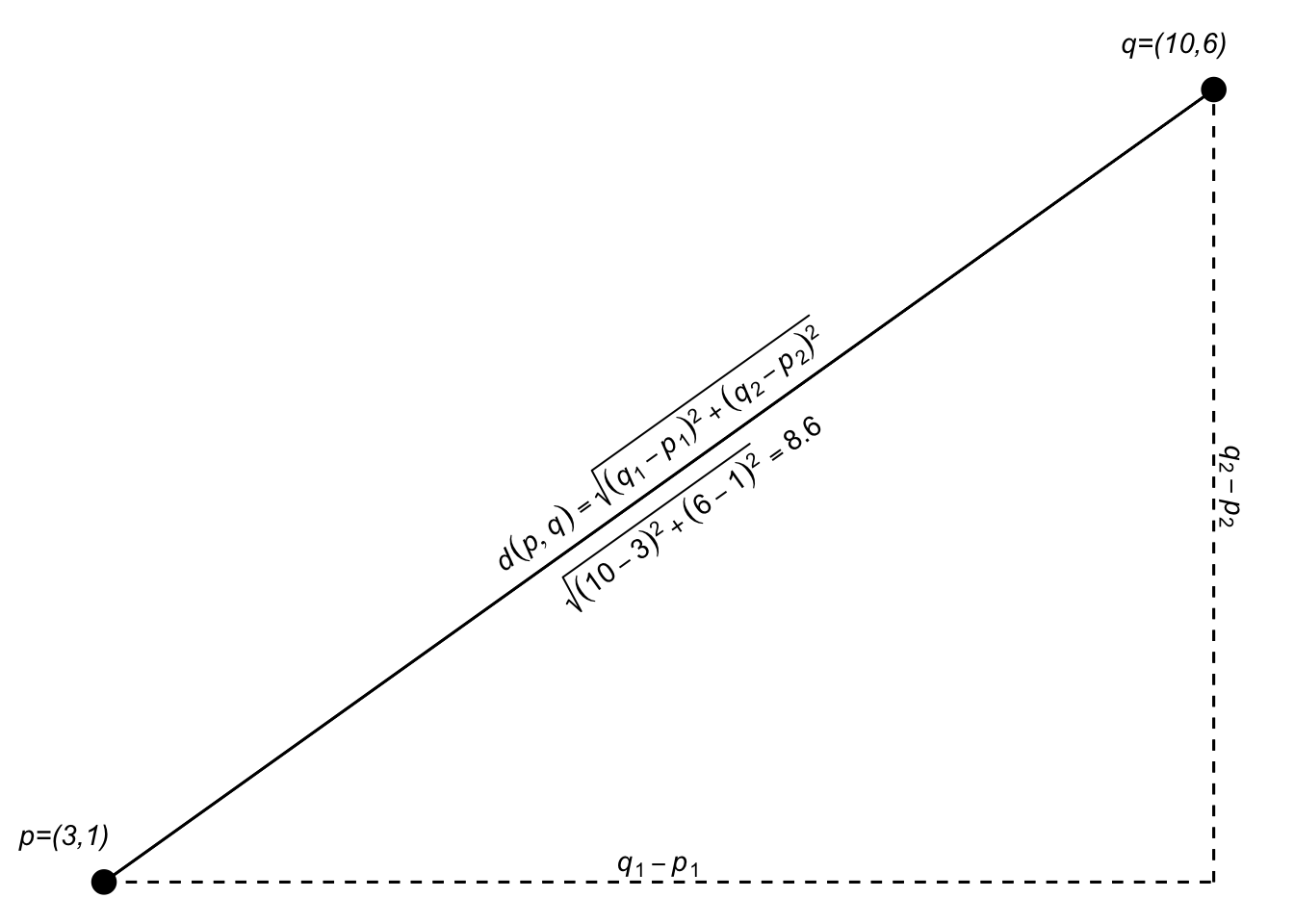
If the points \(p\) and \(q\) are in a two dimensional plane we extend that as: \[d(p,q)=\sqrt{(q_1-p_1)^2 + (q_2-p_2)^2}\]
p <- c(3,1)
q <- c(10,6)
sqrt((q[1] - p[1])^2 + (q[2] - p[2])^2)[1] 8.602325I think I encountered this first as finding the hypotenuse of a right triangle in middle school.
Since we are just adding the two dimensions together, we can generalize that expression a bit as: \[d(p,q)=\sqrt{(q_1-p_1)^2 + (q_2-p_2)^2} = \sqrt{\sum_{i=1}^n(q_i-p_i)^2}\] where \(n\) is the total number of dimensions.
sqrt(sum((q-p)^2))[1] 8.602325In 3D space (like measuring the distance from where you are now to the upper left-hand corner of the room), \(n=3\). Let’s add a third dimension to \(p\) and \(q\) and calculate the distance.
p <- c(3,1,5)
q <- c(10,6,7)
sqrt((q[1] - p[1])^2 + (q[2] - p[2])^2 + (q[3] - p[3])^2)[1] 8.831761Here is an attempt at a 3D plot.
Of course, we can use the generalized equation as well: \[d(p,q)=\sqrt{\sum_{i=1}^n(q_i-p_i)^2}\]
Implemented the same as above using sum:
sqrt(sum((q-p)^2))[1] 8.831761We just did a 3D example and I tried to visualize it. But we can do as many dimensions as we want. Our brains break after 3D but we can add as many dimensions as we like. Here is the 5D Euclidean distance between two points:
p <- c(3,1,5,7,2)
q <- c(10,6,7,13,1)
sqrt((q[1] - p[1])^2 + (q[2] - p[2])^2 + (q[3] - p[3])^2 + (q[4] - p[4])^2 + (q[5] - p[5])^2)[1] 10.72381Or:
sqrt(sum((q-p)^2))[1] 10.72381High-dimensional spaces occur all the time in science. Have four variables to describe something? You have a 4D space and can calculate the Euclidean distance between your observations. Six variables? 6D space and so on. N variables? nD space. It’ll be important as we continue on that you are comfortable with the idea of distances in high-dimensional spaces.
The kNN algorithm uses space explicitly as each variable becomes an equally weighted axis in the \(n\) dimensional space. Because the algorithm for kNN doesn’t teach itself to recognize which variables might be more important than others it’s up to the analyst (that’s you) to build a model sensibly.
The kNN is a dirt simple classifier the assigns membership based on the membership of points that are close by in the parameter space. Typically, the distance is Euclidean as we saw above. The text and materials linked on Canvas explain it all pretty well but I’ll walk through an example based on the fruits and veggies examples in the reading real quick.
foodStuffs <- tibble(culinaryUse = c("vegetable","vegetable","vegetable",
"vegetable","vegetable","vegetable",
"fruit", "fruit", "fruit",
"fruit", "fruit", "fruit"),
item = c("green bean","broccoli","cauliflower",
"cabbage","asparagus","kale",
"apple","organge", "grape",
"banana","peach","blueberry"),
sweetness = c(0.5,0.2,0.2,
0.3,0.3,0.1,
0.7,0.9,0.9,
0.6,0.8,0.7),
crunchiness = c(0.8,0.6,0.9,
0.7,0.6,0.5,
0.7,0.1,0.2,
0.1,0.3,0.2))
foodPlot <- ggplot(data=foodStuffs, mapping = aes(x=sweetness, y = crunchiness)) +
geom_label(aes(label=item,fill=culinaryUse),position = "jitter") +
lims(x=c(0,1),y=c(0,1)) + coord_fixed() + theme(legend.position = "none")
foodPlot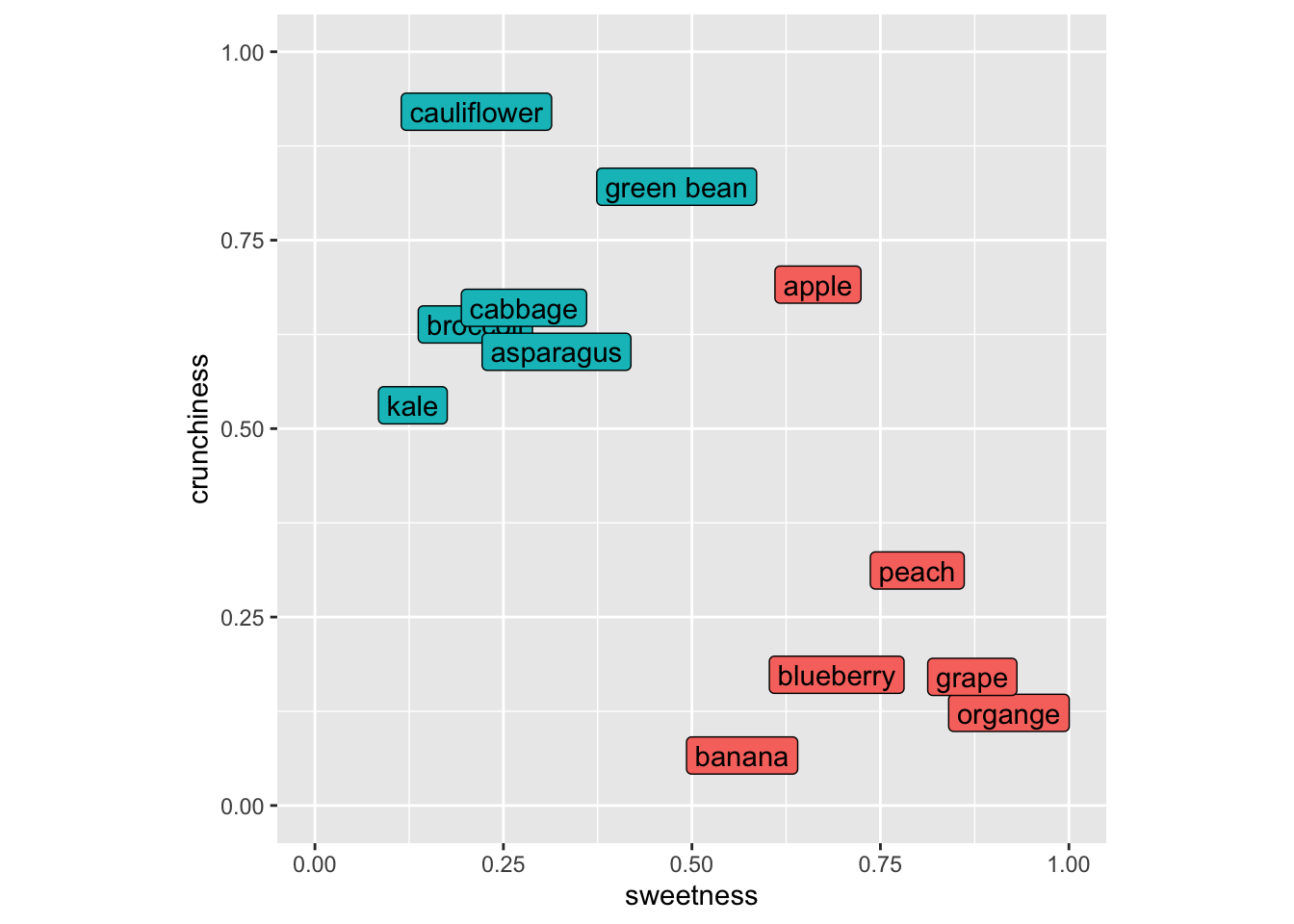
As many of you with botany training know that the fruit/veggie dichotomy is quite different in terms of culinary classification as opposed to biological classification (e.g., green beans, cucumbers, green bears, etc. are all fruits botanically but we use mostly use them as vegetables around these parts at least). So let’s think about these in terms of culinary uses.
Imagine putting in a new item like a strawberry into this space. It’s sweet and not crunchy and we’d call it a fruit using kNN because its nearest neighbors would all be fruits. Let’s do this kNN calculation for, I dunno, eggplant (technically a fruit as well!). Here is my scoring for eggplant and I’ll add it to the plot with a “?”.
eggplant <- tibble(sweetness=0.5, crunchiness = 0.6)
foodPlot + geom_point(data=eggplant, mapping = aes(x=sweetness,y=crunchiness),shape="?",size=7)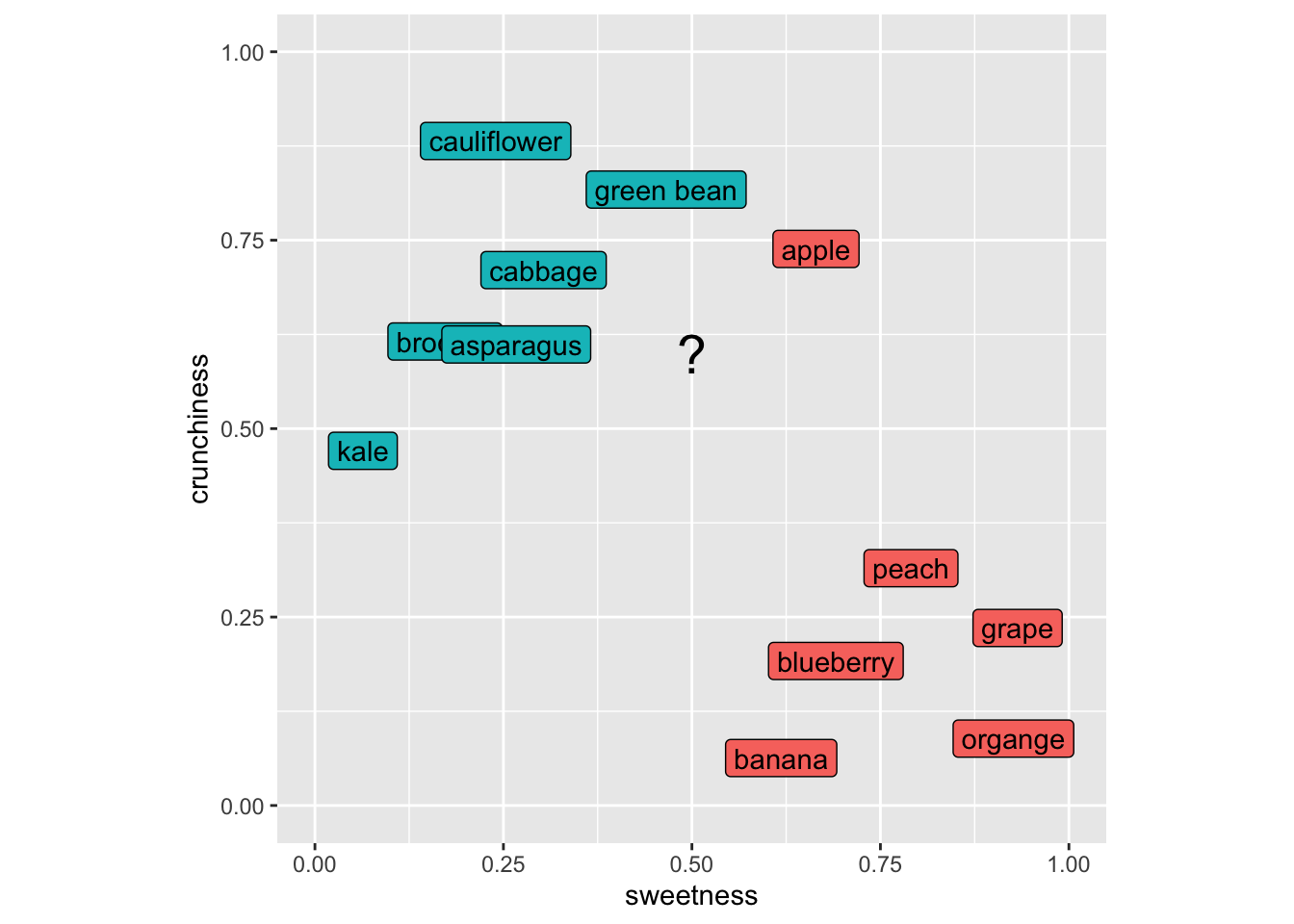
Our first step is to get the distances from our unknown item to all the known items. So here is the distance between green beans and eggplant. Note that this is a 2D space but this approach would work in as many dimensions as we might care to assign to our foods.
p <- foodStuffs %>% filter(item == "green bean") %>%
select(sweetness,crunchiness)
q <- eggplant %>% select(sweetness,crunchiness)
# distance from eggplant to green bean
sqrt(sum((q-p)^2))[1] 0.2And eggplant to blueberry.
p <- foodStuffs %>% filter(item == "blueberry") %>%
select(sweetness,crunchiness)
q <- eggplant %>% select(sweetness,crunchiness)
# distance from eggplant to blueberry
sqrt(sum((q-p)^2))[1] 0.4472136We can use apply to look at the distance from eggplant to all the rows in the foodStuffs data.
p <- foodStuffs %>% select(sweetness,crunchiness)
q <- eggplant %>% select(sweetness,crunchiness)
# distance from eggplant to all the items
dist2all <- apply(p,1,function(x){sqrt(sum((q-x)^2))})
tibble(culinaryUse = foodStuffs$culinaryUse, d = dist2all) %>%
arrange(d)# A tibble: 12 × 2
culinaryUse d
<chr> <dbl>
1 vegetable 0.2
2 vegetable 0.2
3 fruit 0.224
4 vegetable 0.224
5 vegetable 0.3
6 vegetable 0.412
7 vegetable 0.424
8 fruit 0.424
9 fruit 0.447
10 fruit 0.510
11 fruit 0.566
12 fruit 0.640Now, to classify the eggplant we’d ask for a vote based on \(k\). If we asked for the three closest neighbors (\(k=3\)) the vote would be two veggie and one fruit (that crunchy but sweet apple is the minority vote) So we’d call the eggplant a vegetable. The choice of \(k\) controls a tradeoff. Small values of \(k\) lead to very local decisions that can be sensitive to noise (high variance). Larger values of \(k\) produce smoother decision boundaries but can blur meaningful local structure (higher bias).
Make sense? Now this is a trivial example but I will note that ML is being used in cooking and cuisine! Imagine you wanted an ingredient to contrast with your others and had a big database of flavor profiles. You could end up with something really cool (think “curry ice cream” which is awesome) if a ML algorithm helped you find a pattern that you hadn’t thought about before. Google Chef Watson for this in real life.
The reading describes why variables used in kNN have to be on the same scale. I won’t belabor that point here but this is a critical idea. When working in a parameter space that includes many different kinds of variables (length, width, number, whatever) they all need to be scaled to the same frame of reference before you can think about distance. The book uses a min|max normalization from 0 to 1 for all the variables and also talks about transforming to z-scores. In practice, scaling parameters should be computed using the training data only, and then applied to the test data. Computing scaling parameters on the full dataset can leak information from the test set into the model.
You can use categorical data in kNN but that doesn’t mean that you should. Categorical data (e.g., sex in the penguin data) can be used in kNN but would have to be converted into numbers (e.g., 0 and 1) before being used to calculate distance. If you have multiple categories (e.g., island in the penguin data) it’s not clear how you transform those into distance because coding them as integers won’t work. One possibility in that case is to put the categories as numbers equally spaced around a circle – that way the distance between any pair of them is the same but that starts getting complicated fast. kNN might not be the best choice if you have a lot of categorical data that you want to use as predictors.
We are going to follow along with the book and look at the Diagnostic Wisconsin Breast Cancer Database. The data are archived here and I’ve put the csv file on Canvas. As you can read, there are 569 rows (samples) and 30 explanatory variables for the diagnosis (malignant or benign). There is also an id column that we will ignore (never use ID to predict!). The 30 explanatory variables are the mean, standard error, and largest (worst) value for 10 different characteristics of the digitized cell nuclei.
I’m not going to retype the textbook. Read the book along with the code below.
Let’s read the data, shuffle the rows to make sure they are random, drop the id column, and recode the diagnosis column to be a factor.
As you work through the code below, focus on three things:
wbcd <- read_csv("data/wisc_bc_data.csv")
rowShuffle <- sample(x = 1:nrow(wbcd),size = nrow(wbcd),replace = FALSE)
wbcd <- wbcd[rowShuffle,] %>% select(-id) %>%
mutate(diagnosis = factor(diagnosis,
levels = c("B","M"),
labels = c("Benign","Malignant")))And get a count of the response (diagnosis).
wbcd %>% count(diagnosis) %>% mutate(freq = n / sum(n))# A tibble: 2 × 3
diagnosis n freq
<fct> <int> <dbl>
1 Benign 357 0.627
2 Malignant 212 0.373So far we are following along with the book but I’m using tidy syntax. The next step is to normalize the predictor variables to get them on the same scale. The book shows you how to write your own function normalize to get each variable on a scale from zero to one. While I applaud rolling your own functions, I’ll use the rescale function in the scales library which does the same thing. Note that the scales library has all kinds of cool and useful transformations in it.
wbcd_n <- wbcd %>% mutate(across(2:31, rescale))Look at area_mean in the normalized data.
wbcd_n %>% select(area_mean) %>% summary() area_mean
Min. :0.0000
1st Qu.:0.1174
Median :0.1729
Mean :0.2169
3rd Qu.:0.2711
Max. :1.0000 All systems go. Note that one difference here as compared to the book is that I’ve kept the diagnosis column in the data so far. I prefer keeping data together as long as possible but because the books pulls the diagnosis column out, I will bow to pressure and make the labels a separate object here.
wbcd_labels <- wbcd_n %>% pull(diagnosis)
wbcd_n <- wbcd_n %>% select(-diagnosis)Let’s get training and test data. Because the rows have already been shuffled, we can divide using row indices. The book, somewhat arbitrarily, uses 100 rows for the testing data. Because I’ve shuffled the data above (and you will have your own random shuffle), the results will be slightly different between the book, what I have below, and what you get when you run it. But they should be very similar. If they aren’t, that tells you a lot about the stability of the approach.
wbcd_train <- wbcd_n[1:469,]
wbcd_train_labels <- wbcd_labels[1:469]
wbcd_test <- wbcd_n[470:569,]
wbcd_test_labels <- wbcd_labels[470:569]And now we will do the classification using knn.
wbcd_test_pred <- knn(train = wbcd_train,
test = wbcd_test,
cl=wbcd_train_labels,
k=21)Let’s take a look at that object of predictions.
table(wbcd_test_pred)wbcd_test_pred
Benign Malignant
67 33 There are 100 predictions and 64 times the case was classified as Benign and 36 times as Malignant. Because these are the test data we know the real answers for each of these cases. E.g.,:
tibble(preds = wbcd_test_pred, truth = wbcd_test_labels)# A tibble: 100 × 2
preds truth
<fct> <fct>
1 Benign Benign
2 Benign Benign
3 Benign Benign
4 Benign Benign
5 Benign Benign
6 Benign Benign
7 Benign Benign
8 Malignant Malignant
9 Malignant Malignant
10 Benign Benign
# ℹ 90 more rowsThis is the predicted values from knn and the observed (aka truth aka reference) values. They are mostly the same (that’s good!) but sometimes we have a misclassification (that’s bad).
We can evaluate the fit with the aptly named confusion matrix (i.e., which classes are confused with each other). The book uses the CrossTable function from the gmodels library. That’s fine and has all the information you need (run gmodels::CrossTable(x=wbcd_test_labels,y = wbcd_test_pred)) to get the output the book shows. I’m going to show you the output using confusionMatrix function from caret which I see more commonly in the wild.
cm <- confusionMatrix(data = wbcd_test_pred,reference = wbcd_test_labels)
cmConfusion Matrix and Statistics
Reference
Prediction Benign Malignant
Benign 65 2
Malignant 1 32
Accuracy : 0.97
95% CI : (0.9148, 0.9938)
No Information Rate : 0.66
P-Value [Acc > NIR] : 2.113e-14
Kappa : 0.9327
Mcnemar's Test P-Value : 1
Sensitivity : 0.9848
Specificity : 0.9412
Pos Pred Value : 0.9701
Neg Pred Value : 0.9697
Prevalence : 0.6600
Detection Rate : 0.6500
Detection Prevalence : 0.6700
Balanced Accuracy : 0.9630
'Positive' Class : Benign
Don’t freak out at all that information, we will walk through the most important parts. The key part being the table itself (cm$table). It’s just four numbers and look at all we can infer from it!
The predictions from knn are in rows. The truth (aka observed, aka reference) are in the columns. Thus, the top-left corner and the bottom-right corner are the cases that are classified correctly. The lower-left and upper-right corners are misclassifications. In this table we say that a result of “Benign” is a positive result and thus then the lower left shows that there is one false negative (aka type II error) and the upper right shows that there are two false positives (aka type I error).
These errors are summarized in the “Sensitivity” and “Specificity” (those of you that follow the COVID test and vaccine development will be familiar with those terms already). Sensitivity is the proportion of positives (“Benign”) that are correctly identified while Specificity is the proportion of negatives (“Malignant”) that are correctly identified.
The other statistic in that sea that I’ll break down a bit for you is kappa (\(\kappa\)). This is pretty much always reported when you see a classification. The kappa statistic is a number less than one that tells you how much better your classification is performing as compared to a random expectation. It’s calculated as:
\[ \kappa = \frac{p_o - p_e}{1-p_e}\]
where \(p_o\) is the is the observed agreement, and \(p_e\) is the expected agreement. There isn’t a p-value for kappa but you can loosely think about it as a value < 0 means no agreement between the classes, 0–0.20 as slight agreement, 0.21–0.40 as fair, 0.41–0.60 as moderate, 0.61–0.80 as substantial, and 0.81–1 as excellent agreement. A pretty no nonsense but very thorough write up is on stackexchange.
There is a lot more in the confusionMatrix output but that’s enough for now I think. For details on interpreting all the numbers in this function look at the help page. It’s pretty clean: ?confusionMatrix.
The book walks through some of the important aspects and trade offs as you interpret this classification. Is it better for an analyst to worry about false positives or false negatives in terms of patient care? How does changing \(k\) affect this classification? What about the variable normalization? What about the “right” number of predictors to use? I’ll talk about each of these in the video but they are all important considerations.
Let’s use a cool data set of fish caught in Finland in 1917. There are 159 fish from seven species caught from lake Laengelmavesi. In addition to the species there are columns for the weight of the fish (in grams), three measurements of length: 1. Length from the nose to the beginning of the tail, 2. Length from the nose to the notch of the tail, and 3. Length from the nose to the end of the tail. All of the length measurements are in cm. There is also the width of the fish and its height (in cm) as well as the ratio of height to total length and the ratio of width to total length (in percent). The raw data are archived here and formatted nicely in the fishcatch.csv file.
I’m going to read in the file and do some wrangling and cleaning. I’ll drop all the NA values first. I’ll limit the species we are going to classify to just three species. Then I select just four of the variables to predict species (weight, total length, height, and width) which are rescaled from zero to one.
fish <- read_csv("data/fishcatch.csv")
fishFiltered <- fish %>% select(-std_name,-sex) %>%
mutate(common_name = factor(common_name)) %>%
filter(common_name %in% c("bream","perch","pike")) %>%
mutate(common_name = factor(common_name)) %>%
select(common_name,
weight_g,
length_nose2tail_end_cm,
height_cm,
width_cm) %>%
drop_na() %>%
mutate(across(2:5, rescale))Let’s try a 3d view (have to leave out weight for this plot).
library(plotly)
plot_ly(fishFiltered,
x = ~length_nose2tail_end_cm,
y = ~height_cm,
z = ~width_cm,
color = ~common_name) %>%
add_markers() %>%
layout(scene = list(xaxis = list(title = 'Length'),
yaxis = list(title = 'Height'),
zaxis = list(title = 'Width'))) %>%
layout(showlegend = FALSE)What I want you to do is use knn in fishFiltered to classify species using the four variables. You’ll have to specify \(k\) obviously as well as come up with some kind of train and test scheme. You can use knn as above or use the train function in caret if you are feeling ambitious. No matter what, you need to do some cross validation. Summarize your findings. Feel free to expand the species, variables used, or the rescaling as well for those that really like to color outside the lines.